The Secret Behind GPT, BERT, and Advanced Natural Language Models: Transformers
As Natural language processing is becoming better and more human-like, we must know the basics of the root of LLMs.
In 2017, Google Brain published a paper titled “Attention is all you need!”. This paper revolutionized the state of natural language processing abilities tenfold.
Transformers are the class of models that work on the attention mechanisms.
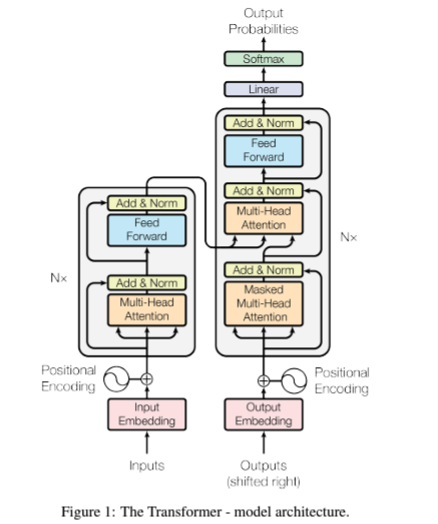 |
| Transformer-Model Architecture by Google |
Do not fret while reading new terminology and the above diagram we will go through the process of how transformers work using an analogy.
Assume we want to write a best-selling novel for that we need a plot outline (words), chapter number(positional encoding), character arcs(attention heads), character interactions(self-attention), multiple drafts(multi-head attention), writing and editing (feed-forward layer), revising and polishing (Layer Normalization and Residual connections), and finally publishing the novel (Decoder).
In our analogy plot outline is words which means the input sentence that we would put into our transformer model.
Positional encoding can be understood by thinking of it as chapter numbers, it gives structure to our novel, telling what words would come in what sequence.
Attention heads are the character arcs of our novel each attention head focuses on different relationships between words in the sentence. One head might focus on the relationship between the subject and the verb, while another might focus on adjectives and nouns.
As we develop our characters we observe how they interact with each other similarly self-attention in transformer allows the model to consider how each word in a sentence interacts with every other word, capturing the context and meaning.
Now our first draft is ready but no one publishes their first work, several drafts are made. In a transformer, these multiple drafts are called multi-head attention where each attention head represents a different perspective on the sentence. These perspectives are then combined to create a more nuanced understanding of the text.
Drafting the Story (Feedforward Layers): Once our characters and plot are well-developed, we start writing the chapters, layering in details, dialogue, and descriptions. This is similar to how the feedforward layers in the Transformer process the input, applying transformations that add depth and richness to the text.
The drafting process is done but to get the best novel we have to revise and polish the novel, in transformer this process is called layer normalization and residual connections it ensures that the output remains consistent and stable, retaining important information from earlier stages while refining the details.
Finally, we can now publish our well-crafted novel, this step in the transformer includes a decoder. The decoder in a Transformer is like the final step in publishing; it takes the refined input (encoded sentence) and generates the final output (a well-structured and coherent sentence or text) ready for the reader (or user).
Congratulations!! You have published a great novel and also understood the intuition behind transformers.
If you need to learn more about transformers and the math behind them you can read the research paper here.


Comments
Post a Comment