Retrieval-Augmented Generation (RAG) Demystified
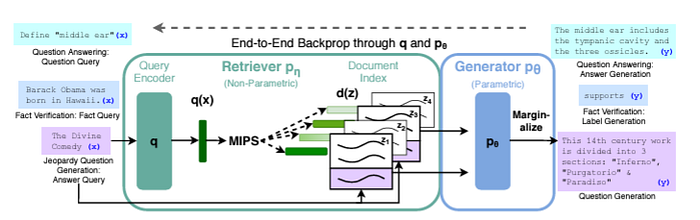 |
| RAG architecture |
We know about LLMs (large language models) and their power to generate content, but they work well only on the training data. If any new information passes through them, LLMs create hallucinations.
To resolve this issue, the Facebook AI research team published a paper on “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” in 2020. They presented the issues with state-of-the-art language models in the paragraph below.
They cannot easily expand or revise their memory, can’t straightforwardly provide insight into their predictions, and may produce “hallucinations” [38]. Hybrid models that combine parametric memory with non-parametric (i.e., retrieval-based) memories [20, 26, 48] can address some of these issues because knowledge can be directly revised and expanded, and accessed knowledge can be inspected and interpreted.
Retrieval augmented generation aka RAGs are generative AI framework that combines LLMs with traditional information retrieval systems. RAG fetches relevant documents to provide context-rich language generation.
There are high level two main concepts in RAG architecture: Indexing and Retrieval and Generation.
Indexing
- Load: In this step, we load the data using document loaders (Document loaders provide a “load” method for loading data as documents from a configured source.)
- Split: The document, “I like hiking” would be split into “I”, “like”, and “hiking”. This allows the model to search through words easily.
3. Store: To store and index our splits, we use the VectorStore and Embeddings model.
Retrieval and Generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Meta describes RAG as follows
“RAG looks and acts like a standard seq2seq model, meaning it takes in one sequence and outputs a corresponding sequence. There is an intermediary step though, which differentiates and elevates RAG above the usual seq2seq methods. Rather than passing the input directly to the generator, RAG instead uses the input to retrieve a set of relevant documents”
Math Behind RAG
1. Retriever: Maximum Inner Product Search (MIPS)
The retriever in a RAG model typically relies on Maximum Inner Product Search (MIPS). Given an input query q, the goal is to find a document d from a corpus D that maximizes the inner product with the query embedding q:

The inner product q⊤d measures the similarity between the query and the document, with the retriever selecting the document that has the highest similarity score.
2. Generator: Conditional Probability of the Output Sequence
Once relevant documents are retrieved, the generator produces the final output. This process is modelled as a conditional probability distribution over the output sequence y, given the input query q and the retrieved documents:

Here, T is the length of the output sequence, y is token at time step T, and y<ty_{<t}y<t represents the sequence of tokens generated before yt. The generator uses the retrieved documents {di} to inform the generation of each token in the output sequence, ensuring that the final response is relevant to the input query.
3. Training Objective: Joint Optimization
During training, RAG models optimize both the retriever and the generator simultaneously. The training objective is to maximize the likelihood of generating the correct output given the input query and the retrieved documents. Formally, the objective can be expressed as:

This objective ensures that the model learns to both retrieve relevant documents and generate accurate responses, improving its performance over time.
Conclusion
Retrieval-Augmented Generation (RAG) represents a powerful convergence of retrieval and generation techniques in NLP.
By leveraging the strengths of both components, RAG models can produce highly accurate and contextually relevant responses, making them indispensable tools in a wide range of applications.
Understanding the mathematics behind RAG not only deepens our appreciation for this technology but also opens the door to further innovations in the field.


Comments
Post a Comment